mZ ask for it and its worth have it i think
https://www.youtube.com/watch?v=954hTT455jg
(Consider start watching from min 27)
mZ ask for it and its worth have it i think
https://www.youtube.com/watch?v=954hTT455jg
(Consider start watching from min 27)
I worked on this yesterday with a student, forking ygg_anderson’s GitHub repo and adding our own file praise_to_and_from.ipynb. Here is our repo:
We did some preliminary analysis on user statistics, including trying to clean the data set by standardizing usernames (we have consolidated variations on Discord usernames due to typos, etc. but still need to cross-reference Discord vs. Telegram) and dates (addressing the fact that some are in EU format, others are in US). We plan to keep working on it before Sunday’s meeting. Forks, questions, suggestions, information welcome.
My main question at the moment is:
What are the variables “v1”, “v1max”, “v2”, etc. ?
Thanks for the chance for me and my students to be involved in this!
 Thank you @octopus !!! So amazing this could be a learning opportunity for your students (I put a shout out to MetaGame here on our graphics as well
Thank you @octopus !!! So amazing this could be a learning opportunity for your students (I put a shout out to MetaGame here on our graphics as well  )
)
 There will be a focused work session this Sunday to do more work on the data. Due to the limited availability of guest data scientists and our wish to expedite the process, discussion will be limited to the work around the data only.
There will be a focused work session this Sunday to do more work on the data. Due to the limited availability of guest data scientists and our wish to expedite the process, discussion will be limited to the work around the data only.
 Everyone is welcome to join, and input is welcome here on the forum for any ideas that are not already included in the HackMD, in regards to analysis.
Everyone is welcome to join, and input is welcome here on the forum for any ideas that are not already included in the HackMD, in regards to analysis.
 The Soft Gov Working Group will be hosting continuing discussion for any other related topics. Thank you for understanding and look forward to watching the live coding and data analysis coordination session!
The Soft Gov Working Group will be hosting continuing discussion for any other related topics. Thank you for understanding and look forward to watching the live coding and data analysis coordination session!

 Add it to your calendar:
Add it to your calendar:
https://calendar.google.com/event?action=TEMPLATE&tmeid=NHZobHEwbWxqOHFkdTNqNG1wbmdmOHVvMWkgNW1rZXAxYWQxajg2MGs2ZzdpN2ZyOHBscTBAZw&tmsrc=5mkep1ad1j860k6g7i7fr8plq0%40group.calendar.google.com
We have consolidated variations on Discord usernames due to typos, etc. but still need to cross-reference Discord vs. Telegram
We have the data in the praise sheet set so that every user has one canonical username in the first column. The data we use for this is in the “DO NOT TOUCH” tab This wasn’t perfect, some duplicates made it thru originally so some corrections have been made in the results tabs of the original spreadsheet but these are easy to capture for the most part… I hope
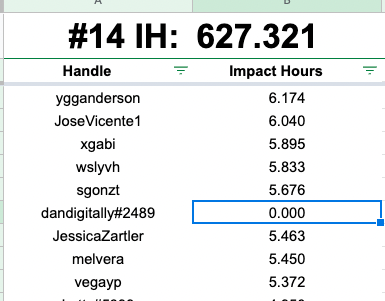
like this one… ddan changed his name a couple times… but all his other names should have been 0’d out.
If you have any other questions about the data, I encourage you to reach out to me and i should be able to answer every question and give advice on how to most effectively process it, I’m sure i can save you a lot of time.
With regard to merging data back into a 1 person 1 record data structure despite the use of multiple platforms, we might want to consider something like MetaGame’s project.json.
It contains json which allows one to define identity merge across multiple platforms. One thing i particularly like about the setup in metagame was that the user themselves provides the identity merge info via a bot in discord.
It may not be the right solution for us right now, but I’d like to flag this as something we can improve upon in the future.
I think it can wait for now; we already have strong uniqueness from the commons stack trusted seed which gives us ETH/xDAI addresses mapped to real life humans! However, those humans end up fractured across their respective points of interaction. Implementing a discord bot that allows those people to bind those IDs back together by updating something like project.json could help reduce complexity in data analysis and make the results of the praise process and things like it more transparent.


-Z
Very interesting…! I’m still debating(with myself) on what schema the data should follow, with regard to being break-proof and being easy to query, for the sourcecred bot
Thanks for pinging me! 
I’ve been wondering over true unique keys with which to query the data.
Initially, I settled on discord-id, but reading this, I realise that this might fail in cases of people changing their discord account.
The current storage form is-
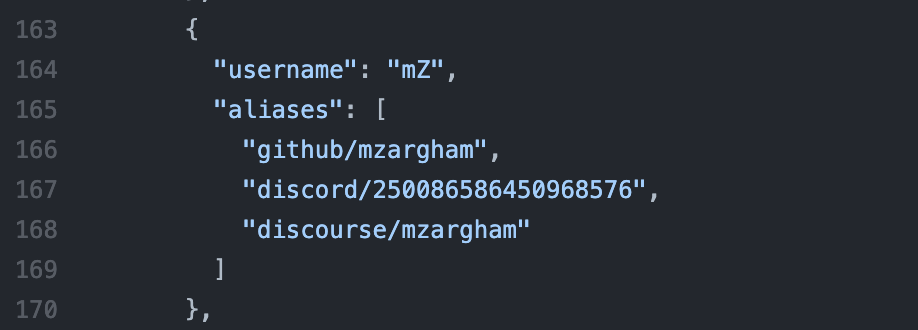
users: Collection([
{
_id: uniqueObjectId from mongo,
id: <discord-id>,
username: <discord-name>#<discord-discriminator-tag>
github_username: <github-uname>,
forum_username: <forum-uname>,
wallet_address: <ETH-address>
},
{
... same fields as above for different users
}
])
There is an apparent lack of schema here, so that the user can be directly queried via any of the fields(I have to write some pre-data entry logic to ensure that they’re unique). But, I think canonical names would indeed make really good points of consideration, since the Praise distribution uses that. I think I should maybe add an extra field, or maybe adopt a version of the Metagame format.
(The only issue with keeping a list of aliases is that it’s not a direct key(not directly queryable from the API, thus needing to load up all of the data, which might get slow), and hence it’s going to identify users using just with their github/discord. *harder, but totally doable).
The reason for keeping _id is to ensure that there is always one context key that doesn’t change and is permanent. (even the canonical names can change, given time). I agree that the ETH addresses from Trusted seed application are the most valid data with respect to verifying humans. However, in future cases, I think these could also be changed(wallet keys lost or some similar situation from a user)
This data is in JSON(stored on Mongo, and thus directly query-able). Moreover this format could easily be turned to a single SQL table/spreadsheet/CSV files for data analysis
I’ve updated with what I was able to do in terms of cleaning/standardizing the data we already have:
It’s all here: github.com/andrewpenland/praiseanalysis
Resulting data is in “cleaned-non-quantifier-data.csv”. Process/walkthrough is in “cleaning-praise-data.ipynb”
Thank you for the chance to work on this! All feedback welcome.
Thank you everyone for a great session today everyone!!! With a special thanks to @octopus @ygg_anderson for leading the heavy lifting on getting the data work going. Here is the HackMD with the research questions and notes so far:
We will be scheduling a session for Tuesday focusing on categorizing the praise. Will post soon
You are all warmly invited to a hack session tomorrow at 12pm EST / 6pm CET on the TEC Discord - Parameters Voice channel focused on creating Praise “categories” to look at the distribution through that lens - look forward to seeing you there!
Hi!
There is a lot of incredible materials to read here!
One question regarding praise and work on TE: are you considering hours by contributors on the TE Community repos that have been working in paralel of TEC and unaware of the praise system, but that are valuable to TE Academy / Community?
In our case, I’m talking about Balancer Simulations. Here for example there was a lot of work by Angela and Vasily that is nor reflected in commits and we didn’t measure by praise.
Is Token Engineering Community separate from the Commons?
A quick update: we had a very productive session yesterday to start the work on categorizing contributions. You can see the work here Praise Categories - Google Tabellen and feel free to add comments or input using the comment function in the doc or replying here. Also, here is the handy link to the full notes/work/Github links in this HackMD we are using.
Our next work session is Sunday - we could really use help then to do some praise grouping - which is heavily manual, and would be quicker with help
Warmly invite you to join and support this work which will be an important next step in getting this analysis completed

Add it to your calendar:
https://calendar.google.com/event?action=TEMPLATE&tmeid=MmZkNG1ubWxjYXEzNmw0NTlmbGZsbDZqbW8gNW1rZXAxYWQxajg2MGs2ZzdpN2ZyOHBscTBAZw&tmsrc=5mkep1ad1j860k6g7i7fr8plq0%40group.calendar.google.com
@Raul For sure! Yes, that is part of the work and what we are looking at, is how we have valued, not valued, “overvalued” or “undervalued” various contributions - and more so, the general distribution %s. This is reflected in this category sheet but if you had any other comments, or would like to participate in this work, we would be super lucky to have you! I know you are busy as well, so if not and just want to add more thoughts a-sync we welcome your thoughts and input Also opportunity on the modeling/data science side to jump in if you would be interested in the work any time is appreciated.
Other projects have shown interest in using the Praise System, so this work goes beyond just this instance, as we look at reward system patterns. Thanks so much for commenting on this thread - so nice to hear from you!
Oh and about TE Community and relationship to TEC - the TE community is a HUGE part of the Token Engineering Commons, but they are “separate” as “organizations.” The idea for TEC came out of the TE community, and is meant to create an economy to advance the field of Token Engineering. So in the initialization of the TEC, we are looking at balancing rewarding those who supported the build of the TEC, and those who are contributing to the field - it is still very much up for discussion and the reason why we are digging into the rewards system analysis - to see if the system/algorithm achieved the goals of the community - so your voice and input is very important as well in this discussion, as it would be great to hear from the wider community, and have participation in this discussion and any votes we hold to make decisions on this topic.
Hello everyone! I have some new stuff to share in praise analysis on distribution, the potential impact of UBI, and word/type/categorization analysis.
If you are interested in attending a Zoom meeting at 9 AM EST (noon GMT/3 PM CET) where I will go over some of our progress on Praise, please meet me here:
More information:
andrew octopus is inviting you to a scheduled Zoom meeting.
Topic: andrew octopus’ Zoom Meeting
Time: Jun 11, 2021 09:00 AM Eastern Time (US and Canada)
Join Zoom Meeting
Meeting ID: 836 7971 3518
Passcode: CtHkj3
For anyone who is interested, here are the links to recordings of the call:
Part 1: 06/11/21 Praise Distribution Discussion Part 1 - YouTube
Part 2:

Looking forward to discussing this more. I know some other data people have ideas and progress to share, too.
Edit - Update: Using the invaluable discussion from yesterday (video in previous post), l made some progress on analyzing retweet Impact Hour data.
It’s not hard to identify the retweets, since “retweeting” was consistently used.
Problem: it is a bit hard to get the IH per retweet, since these values were sometimes hand-edited by the quantifiers if they felt the total IH for an individual was underestimated based on their initial calculations.
Assumption: We are going to assume that for a given period, all retweets were worth the same amount, which was given by the mode (most common IH value) of the retweet praises.
For instance, in period 7:
I would then assume that the values 1.98 and 4.24 are edits, replacing them with 0.26. For data purposes, this just becomes 17 values of 0.26 IH.
I am making this assumption throughout: that the mode IH value of retweets for a given period represents the “real” value, and any deviations from that are hand edits that can be replaced.
This makes the analysis a lot easier, so we can make some basic statements like:
We can do a breakdown period-by-period and provide some graphs, but I wanted to go ahead and provide the answer to this question since it had been repeatedly raised in meetings.
All feedback welcome. ![]()
Wow!! Thank you octopus for the Recordings and the great data on twitter! PRAISE!
I worked a bit this morning on making it so the data can be hand-labeled by people who are interested in that.
Here is a video giving an overview of how I see hand-labeling might work:

Here is the place where you can label data if you wish:
https://docs.google.com/spreadsheets/d/1ldBplIrHG8nWBxAa8pTgxX2OxTBx976ia51MC1ZhVXc/edit?usp=sharing
One note:
there are currently 25 human-generated labels with some overlap. It might be helpful to merge later into fewer categories
Hope this is useful.![]()
We discussed a few possible approaches for proposals moving forward with the analysis in soft gov today. It was a discussion call where everyone present was able to share their opinions. I think is worth sharing some of the sentiments here, specially the 2 most polarized ones:
The analysis is great for implementing future changes that won’t affect the already quantified praise and Impact Hour set. The distribution we have now is seen as the results of agreements and expectations that shouldn’t be changed retroactively in favor of the trust built in the community so far.
The analysis could possibly change the IH set we have so far via proposal making because it is offering relevant information that we didn’t have before. The distribution we have now is seen as skewed and unfair because agreements and expectations were stablished without enough insights of their consequences.
I think this is the first debate we should have that will greatly affect how we move forward with the process and what is the scope of the proposals we will have.
I’ll tag a few people for advice process here.
@ygg_anderson @octopus @Griff @santigs @ZeptimusQ @JeffEmmett @JessicaZartler @Tamara @Suga @sem @Solsista @mzargham
Thank you @liviade for this update and advice process.
In the Stewards call now, @ygg_anderson is looking to create a summary of the Praise System analysis, and initial suggestions for a possible intervention.
I feel we should schedule a discussion with a more diverse and larger group of stakeholders who will be affected by this decision and would like to have a voice and input in this process, especially those who could not attend this last meeting. I propose we advertise this discussion/agenda at least three days in advance - to hear more points of view and together, discuss possible proposals going forward, and a process by which we decide on those proposals.
I propose we hold this session next week during the regularly scheduled Soft Gov meeting next Tuesday, June 22 OR, maybe a time that is more friendly to those in Europe/CET?..
I also would like to say that trust building is an ongoing process, and this is a huge part of it. When we realize that our systems aren’t serving part of our community, and that part of the community is asking to be heard, how we respond is part of building trust as well.
The agreements that were made, were made several months ago (August 2020 / December 2020) with only a total of <10 votes. Should a community of hundreds have to abide by 10 people’s decision six months ago? Or should we now re-assess, hold a vote, and hear more voices with the information we have now?
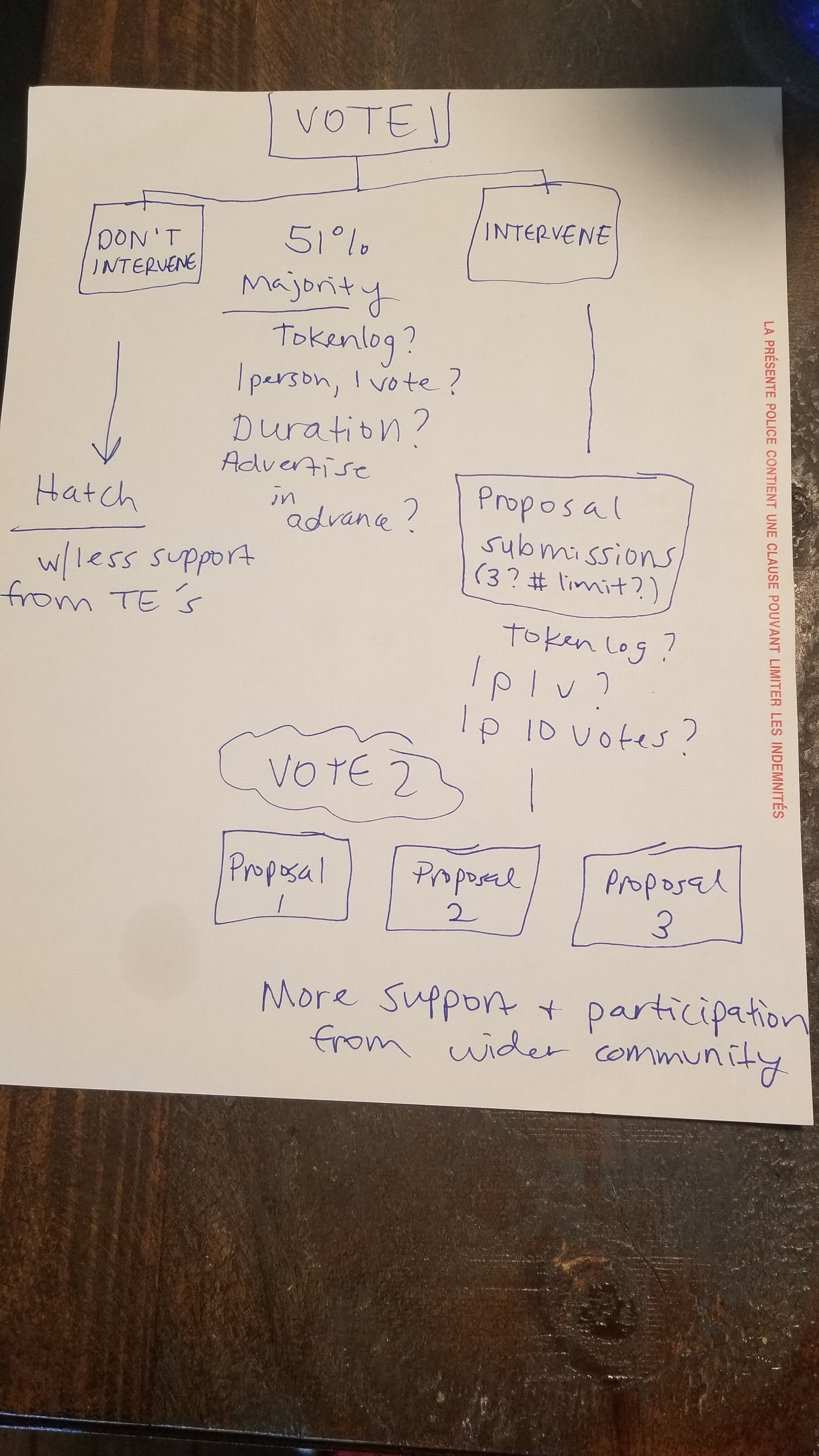
These are questions to consider - so, I think meeting with a larger group, hearing everyone’s voices once again, and then put it to a vote. We could vote on whether or not to have an intervention first, and if the community decides to intervene - do a similar process to the Hatch Configuration process - we could do with or without the forking depending on time constraints for the hatch - let’s discuss the decision space and process, would love to hear everyone’s ideas.
Here is a sketch: