Discussing token distributions and payments is really hard and rarely is done publicly (outside of communities with sourcecred :-D)
Money is a really weird thing, and it has a tendency to be challenging in relationships and I’m really proud of how openly we can talk about all this distribution.
I’m here again I don’t believe it myself this is fun and addictive (the politic side). Pls if something sounds rude or very straight forward its not my intention, my main goal its to share my thoughts and keep learning from you guys. For me, it’s very important, we stick together.
It would be awesome to apply data science and see the results, I honestly think they wouldn’t be much different tho (if we don’t modify the data). Humans are really good at using the eye to get the result. For example, a group of friends go to dinner together and at the time of payment we distribute it equally. Then a member complains that I have consumed less. In two minutes the accounts come out, this person has consumed more and add 10 euros and these two who consumed less pay 5 euros less each. It’s not 100% accurate but it’s very accurate and the cost of doing it 100% accurate takes more effort.
With this little exemple i’m not trying to say we don’t have to be accurate in the future. But the results it self should be pretty accurate. Do a new distribution at the last minute might not be the best thing. How will contributors act after a change? I think this would create more conflict than solution even if the change is little. I’m really against changing past decisions. We are on blockchain after all.
Another argument I have against it’s really not the moment, it’s go time. We had plenty of time before to check and update our rules. Specially on december i was really not happy how we approach praise (at that moment i wasn’t good enough to write like i’m doing now so thanks you so much TEC , still plenty of room to grow and that excites me)
I really agree with sem (i would change fair for legit) but would be nice more engagement from the community, specially stewards
Yeah that’s so true it’s not something I personally agree with. If someone wants to join our common and contribute to advance TE field , anyone is welcome specially TEs. That being said I would love to hear what would be the redistribution we are talking about and how that would benefit TEC.
I’m so sorry about the misunderstanding, I was not referring to what Jean-Jacques Rousseau wrote in 1762 there is no state here. What I really mean when using social contract it’s that there are rules, boundaries and agreements in TEC that we shouldn’t break for the well-being of the common. TEC cares about the individuals (TEC needs them) but the main goal it’s advancint TE. That’s how I see it. In the long run having a TE public goods will help the individuals.
The onboarding document (i can’t find the english version) was talking about IH around 20-200. The human eye :p. Every blog post that happened every 2 weeks I was understanding that all these people were adding this money to the hatch (20-200$) in the case we succeed.
That’s why talking about redistribution makes me untrust the process.
I honestly agree with you here, I’m not sure how well the process will end. It was very open and it’s scary to see the future but also exciting. I feel like trusting our governance culture but that’s my personal feeling.
Democratic doesn’t mean it’s good, Hitler took power via democracy. I really love the blockchain space culture “skin in the game”.
One thing it’s modify the rules for a better being of the community looking to the future with the consensus of this one. But if I don’t understand it wrong, what it’s being suggested here is to change the actual distribution which means change the past and remove value from some individuals to add it to another. How are we going to handle that?.
That being said, TEC should care more for the TE field than for individuals. If there is a strong argument that would benefit the TE field in the long run we should consider it, so please share. And if yes, does it need to be done asap? why?
I really think that what you are suggesting must be done. It adds value to the TE field 100%. But I’m personally really concerned with the topics mentioned above.
NEW TIME: The data science session will begin at 4pm EST / 10pm CET - Apologize for any inconvenience, and if you cannot attend, we will have a follow up session scheduled farther in advance Look forward to seeing you there!
A huge THANK YOU to the community for engaging in the kick off meeting to research and analyze the Praise System!
We will be holding a focused data science session this week to employ the help of our subject matter experts in analyzing the data and posting follow ups as things progress.
In the meantime, see below and look forward to sharing updates as the work progresses:
Here is the Hack MD where we sketched all of the ideas for what data slices to look at
We are working with Angela Kreitenweis, founder of TE Community & Academy. She called this an “admirable action” and feels deep respect for the community to be willing to question these systems and processes, and is excited to join the community on this token engineering initiative and a wonderful educational opportunity. She gives her full support and is working very hard to coordinate with data scientists for a live coding session to begin digging into this work as soon as possible.
We are putting together a hack session with a group (3-5 + data science Masters/PhD students) of the top data scientists in TE community next Tuesday and ahead of that, will have a focused working session in TEC Labs on Sunday (TBA).
Will post here and on Twitter events as they are scheduled.
Thank you so much for coordinating this effort Jess, let us know if any session will happen today, mainly I want to learn and just watch during this sessions, and help however is possible.
Hey Jess, you are telling TE they will have more IH tokens? They will feel disappointed when that doesn’t happen. Our reputation will decrease. Even if TE don’t have as much governance of the commons, they still will receive funding pool funds for their work and if they decide they can buy TEC tokens as well
Could you tell me what do you think about my arguments in the previous post, pls?
Data will tell you whatever you ask for it. Will data tell you all those IH whales (not whales of the common which look like its not being understood) had to sell their crypto on a bull market to be here full time?
Hi Zepti, I am not sure where you got that impression, I am not telling TE anything about tokens. I am asking for data scientist to review different parts of the data, based on suggestions submitted by the community in the meeting last Sunday, and in the Soft Gov meeting yesterday.
I don’t want to engage in debate or convince anyone as I am not advocating for any particular action, except to have a deeper look at the data, based on the suggestions by the community.
The data scientists that we are asking have no stake in this system. Only Shawn, Sem and Andrew Shinichi (who may or may not participate in the analysis) have any stake or Impact Hours. The others, who will be doing the majority of the work, are impartial and have no Impact Hours, and will not be affected by any decisions made by the community or the outcome.
The main look - at distribution, is not a subjective matter and has percentages that exist as fact. Anyone is welcome to submit suggestions for what aspects we should look at, and the sessions will be open, pre-advertised and recorded.
I worked on this yesterday with a student, forking ygg_anderson’s GitHub repo and adding our own file praise_to_and_from.ipynb. Here is our repo:
We did some preliminary analysis on user statistics, including trying to clean the data set by standardizing usernames (we have consolidated variations on Discord usernames due to typos, etc. but still need to cross-reference Discord vs. Telegram) and dates (addressing the fact that some are in EU format, others are in US). We plan to keep working on it before Sunday’s meeting. Forks, questions, suggestions, information welcome.
My main question at the moment is:
What are the variables “v1”, “v1max”, “v2”, etc. ?
Thanks for the chance for me and my students to be involved in this!
Thank you@octopus !!! So amazing this could be a learning opportunity for your students (I put a shout out to MetaGame here on our graphics as well )
There will be a focused work session this Sunday to do more work on the data. Due to the limited availability of guest data scientists and our wish to expedite the process, discussion will be limited to the work around the data only.
Everyone is welcome to join, and input is welcome here on the forum for any ideas that are not already included in the HackMD, in regards to analysis.
The Soft Gov Working Group will be hosting continuing discussion for any other related topics. Thank you for understanding and look forward to watching the live coding and data analysis coordination session!
We have consolidated variations on Discord usernames due to typos, etc. but still need to cross-reference Discord vs. Telegram
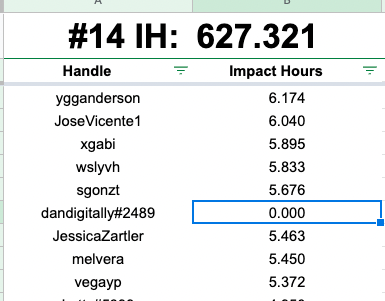
We have the data in the praise sheet set so that every user has one canonical username in the first column. The data we use for this is in the “DO NOT TOUCH” tab This wasn’t perfect, some duplicates made it thru originally so some corrections have been made in the results tabs of the original spreadsheet but these are easy to capture for the most part… I hope
like this one… ddan changed his name a couple times… but all his other names should have been 0’d out.
If you have any other questions about the data, I encourage you to reach out to me and i should be able to answer every question and give advice on how to most effectively process it, I’m sure i can save you a lot of time.
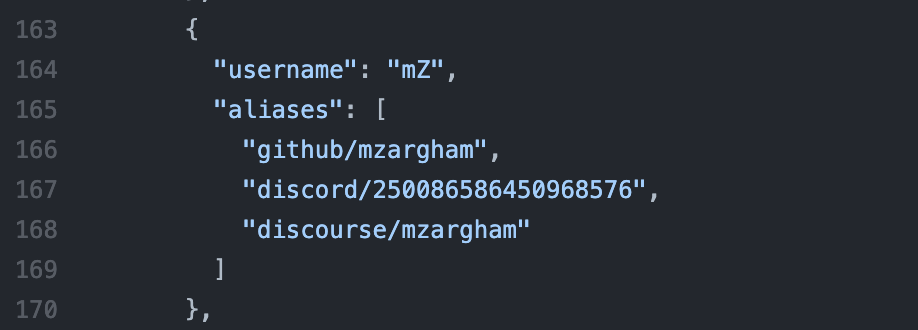
With regard to merging data back into a 1 person 1 record data structure despite the use of multiple platforms, we might want to consider something like MetaGame’s project.json.
It contains json which allows one to define identity merge across multiple platforms. One thing i particularly like about the setup in metagame was that the user themselves provides the identity merge info via a bot in discord.
It may not be the right solution for us right now, but I’d like to flag this as something we can improve upon in the future.
I think it can wait for now; we already have strong uniqueness from the commons stack trusted seed which gives us ETH/xDAI addresses mapped to real life humans! However, those humans end up fractured across their respective points of interaction. Implementing a discord bot that allows those people to bind those IDs back together by updating something like project.json could help reduce complexity in data analysis and make the results of the praise process and things like it more transparent.
Very interesting…! I’m still debating(with myself) on what schema the data should follow, with regard to being break-proof and being easy to query, for the sourcecred bot
Thanks for pinging me!
I’ve been wondering over true unique keys with which to query the data.
Initially, I settled on discord-id, but reading this, I realise that this might fail in cases of people changing their discord account.
The current storage form is-
users: Collection([
{
_id: uniqueObjectId from mongo,
id: <discord-id>,
username: <discord-name>#<discord-discriminator-tag>
github_username: <github-uname>,
forum_username: <forum-uname>,
wallet_address: <ETH-address>
},
{
... same fields as above for different users
}
])
There is an apparent lack of schema here, so that the user can be directly queried via any of the fields(I have to write some pre-data entry logic to ensure that they’re unique). But, I think canonical names would indeed make really good points of consideration, since the Praise distribution uses that. I think I should maybe add an extra field, or maybe adopt a version of the Metagame format.
(The only issue with keeping a list of aliases is that it’s not a direct key(not directly queryable from the API, thus needing to load up all of the data, which might get slow), and hence it’s going to identify users using just with their github/discord. *harder, but totally doable).
The reason for keeping _id is to ensure that there is always one context key that doesn’t change and is permanent. (even the canonical names can change, given time). I agree that the ETH addresses from Trusted seed application are the most valid data with respect to verifying humans. However, in future cases, I think these could also be changed(wallet keys lost or some similar situation from a user)
This data is in JSON(stored on Mongo, and thus directly query-able). Moreover this format could easily be turned to a single SQL table/spreadsheet/CSV files for data analysis
I’ve updated with what I was able to do in terms of cleaning/standardizing the data we already have:
standardizing dates (year first vs. year last)
making room where praise was dished easier to see
giving each user their standard name from the “DO NOT TOUCH” list, plus trying to catch case issues. As best I could, each praise instance now maps to a standard ID that matches their CSTK ID if possible.
Thank you everyone for a great session today everyone!!! With a special thanks to @octopus@ygg_anderson for leading the heavy lifting on getting the data work going. Here is the HackMD with the research questions and notes so far:
We will be scheduling a session for Tuesday focusing on categorizing the praise. Will post soon
 I don’t believe it myself this is fun and addictive (the politic side). Pls if something sounds rude or very straight forward its not my intention, my main goal its to share my thoughts and keep learning from you guys. For me, it’s very important, we stick together.
I don’t believe it myself this is fun and addictive (the politic side). Pls if something sounds rude or very straight forward its not my intention, my main goal its to share my thoughts and keep learning from you guys. For me, it’s very important, we stick together.
 , still plenty of room to grow and that excites me)
, still plenty of room to grow and that excites me) Look forward to seeing you there!
Look forward to seeing you there!


 Thank you
Thank you  There will be a focused work session this Sunday to do more work on the data. Due to the limited availability of guest data scientists and our wish to expedite the process, discussion will be limited to the work around the data only.
There will be a focused work session this Sunday to do more work on the data. Due to the limited availability of guest data scientists and our wish to expedite the process, discussion will be limited to the work around the data only. Everyone is welcome to join, and input is welcome here on the forum for any ideas that are not already included in the HackMD, in regards to analysis.
Everyone is welcome to join, and input is welcome here on the forum for any ideas that are not already included in the HackMD, in regards to analysis. The
The 
 Add it to your calendar:
Add it to your calendar: