I’ve been thinking about Conviction Voting again now that Gitcoin is starting to play with it. What I’m now seeing is that the decision to use Effective Supply (the amount of tokens that are actively voting on proposals in Conviction Voting) as the denominator in determining a given project’s conviction (the numerator is the number of tokens staked on a given proposal) is behind some of CV’s unexpected behaviors. In particular, it helps explain the strange phenomenon we experienced where projects with relatively low conviction would suddenly and quite unexpectedly lurch past the conviction threshold.
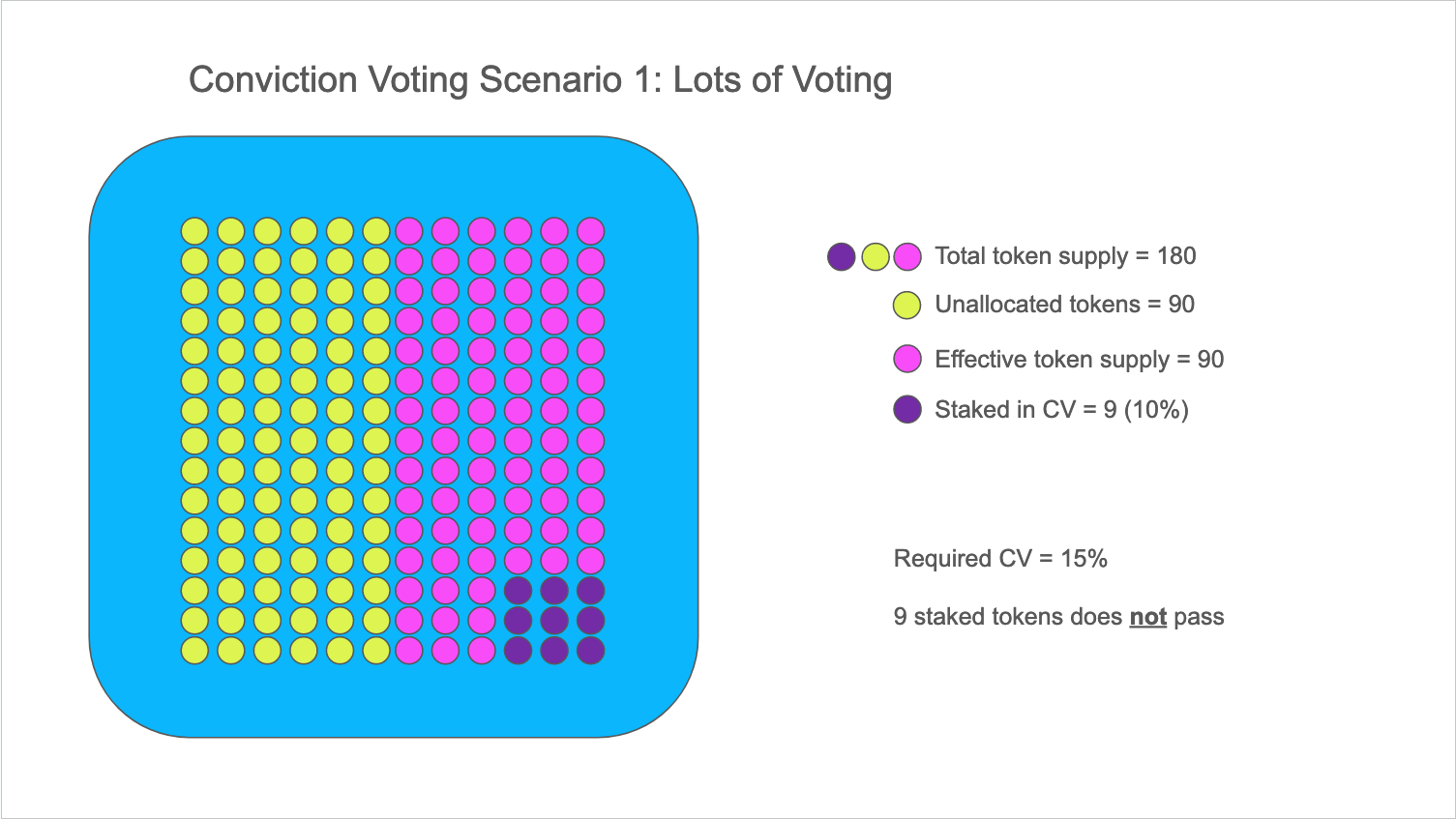
To illustrate, let’s assume two scenarios: one with high levels of voter engagement and one with relatively low levels of engagement. In both cases, we’ll assume that a particular project has the same number of tokens staked on it (the purple tokens - or 9 in both cases). Yes, I’m simplifying a bit of how CV actually works in order to hone in on the disproportionate role that I believe the effective supply plays.
In this first case, there are lots of people voting on other projects (pink tokens); these are the allocated tokens, which constitutes the
effective supply (90 tokens). The “conviction” ratio in this case, is 10% (9/90). If the CV ratio required to pass is 15%, the project will
not pass.
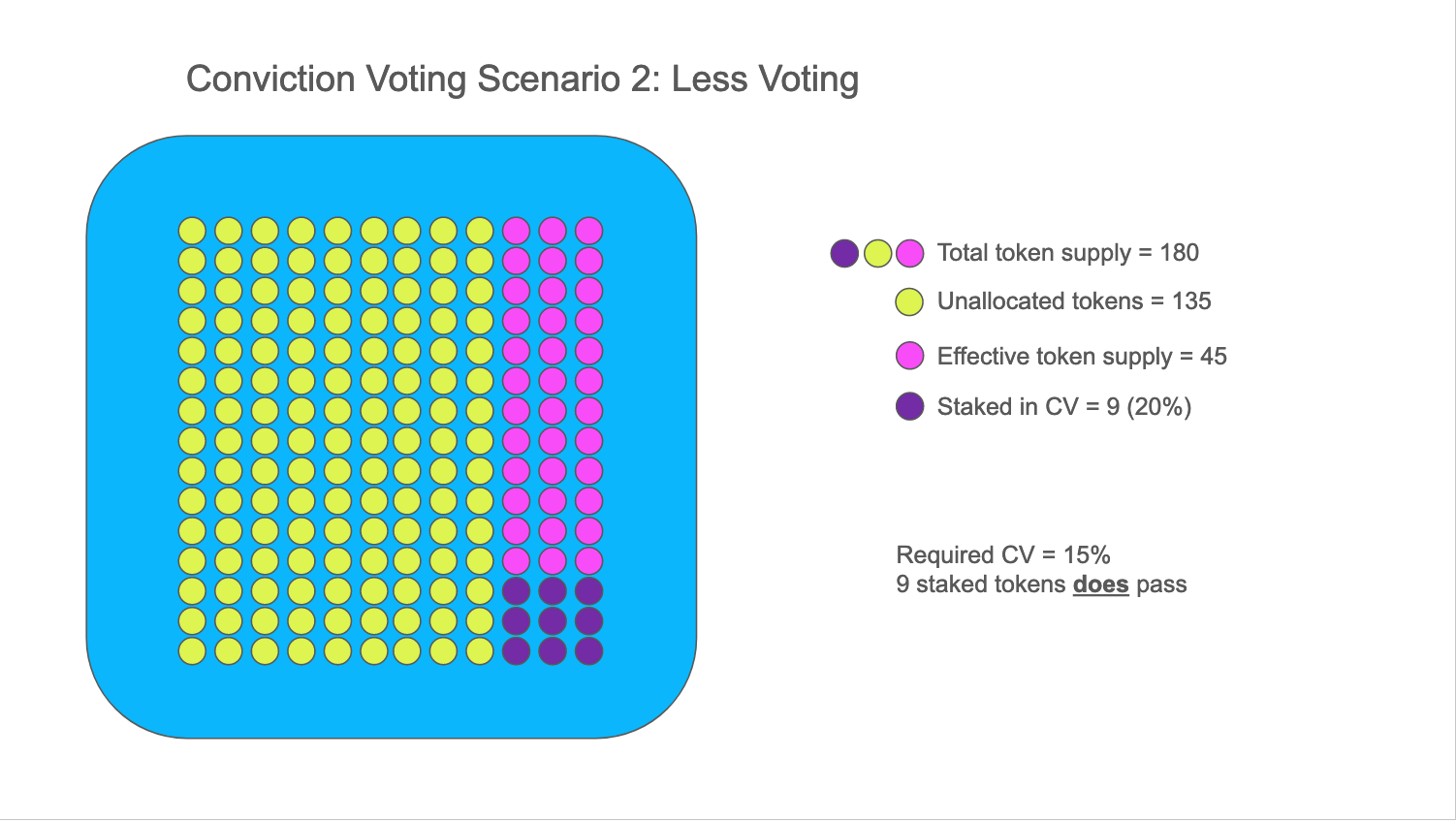
In the second case where there is much less voting, allocated tokens drop and the
effective supply drops to 45, which makes the conviction ratio jumps to 20% (9/45). Now, with that same required CV ratio of 15%, the project
does pass.
So, how does this explain the phenomenon of projects suddenly passing? At some point, I think we must have realized that the low level of voting we were experiencing (i.e. a low effective supply) was making it easier than expected for projects to pass. So, we deployed a creative hack of introducing an “abstain” project that token holders could use to stake their tokens and thereby increase the size of the effective supply (more allocated tokens). This boosted the denominator, which had the effect of requiring more conviction (a bigger numerator).
The surprise we ran into was when voters temporarily took tokens off of the abstain project to vote on a project they cared about - but then forgot to put it back on. The result was that the effective supply would drop dramatically and thereby dramatically decrease the amount of required conviction. And, boom, a project with relatively low conviction that seemed unlikely to pass for a long time would suddenly zoom pass the finish line and be funded.
@JeffEmmett, I’m pinging you because I know you’re interested in this and am wondering whether you have any insight around the decision to use effective supply, rather than say the total supply. I seem to remember Griff saying at one point that part of the design behind CV was to stimulate treasury expenditures, and I’m wondering if that was part of the rationale? Also, what do you think might be the impact of using total supply instead?
@octopus, I’m pinging you because were the one who got us digging into this again.